Towards a Multi-modal, Multi-task Learning based Pre-training Framework for Document Representation Learning
Abstract
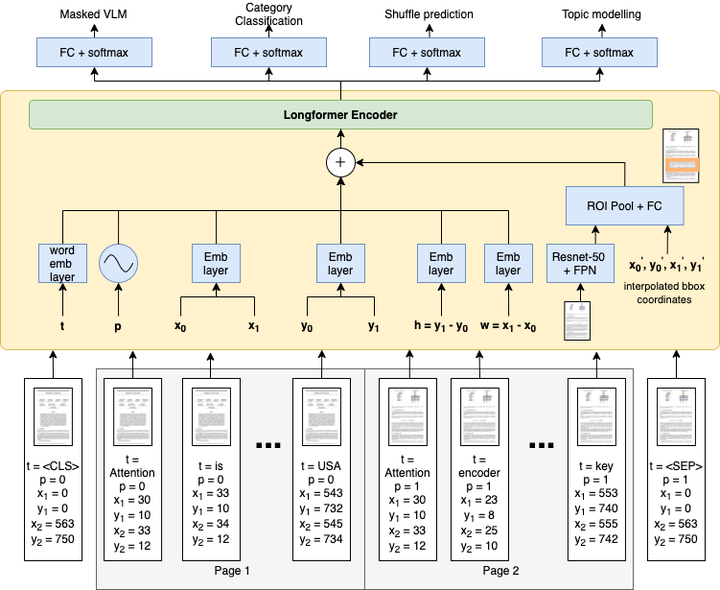
In this paper, we propose a multi-task learning-based framework that utilizes a combination of self-supervised and supervised pre-training tasks to learn a generic document representation. We design the network architecture and the pre-training tasks to incorporate the multi-modal document information across text, layout, and image dimensions and allow the network to work with multi-page documents. We showcase the applicability of our pre-training framework on a variety of different real-world document tasks such as document classification, document information extraction, and document retrieval. We conduct exhaustive experiments to compare performance against different ablations of our framework and state-of-the-art baselines. We discuss the current limitations and next steps for our work.