Abstract
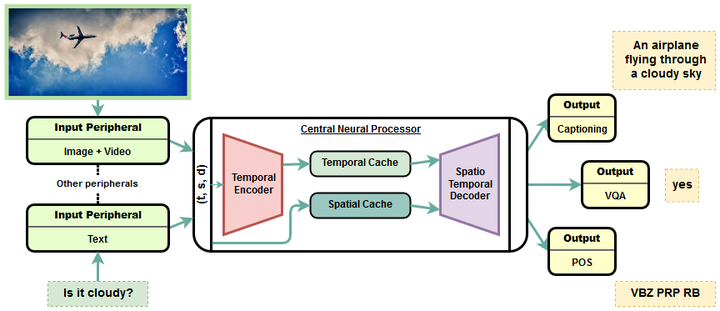
Transformer is a popularly used neural network architecture, especially for language understanding. We introduce an extended and unified architecture that can be used for tasks involving a variety of modalities like image, text, videos, etc. We propose a spatio-temporal cache mechanism that enables learning spatial dimension of the input in addition to the hidden states corresponding to the temporal input sequence. The proposed architecture further enables a single model to support tasks with multiple input modalities as well as asynchronous multi-task learning, thus we refer to it as OmniNet. For example, a single instance of OmniNet can concurrently learn to perform the tasks of part-of-speech tagging, image captioning, visual question answering and video activity recognition. We demonstrate that training these four tasks together results in about three times compressed model while retaining the performance in comparison to training them individually. We also show that using this neural network pre-trained on some modalities assists in learning unseen tasks such as video captioning and video question answering. This illustrates the generalization capacity of the self-attention mechanism on the spatio-temporal cache present in OmniNet.